
We recently published a blog describing our LLM-prompting experiment in which we created a Google Calendar export/publication feature. The feature allows users to publish events within the Ruoom open source CRM calendar to their personal Google Calendar.
Just like our first LLM prompting experiment (and as noted in our first review blog), we ended the blog with a functional feature that did what we asked of the LLM.
But just because it’s a working feature doesn’t make it a good feature, or one that won’t cause issues in our larger codebase.
In this blog, we’ll take a look under the hood at the code quality.
Reviewing the Code
We have all of our code posted to our public repository: https://github.com/Ruoom/ruoom-core/
The code for this experiment was pushed to a specific branch found at: https://github.com/Ruoom/ruoom-core/tree/llm_experiment/gcal_export
We have isolated only the changes made by the LLM at the commit: https://github.com/Ruoom/ruoom-core/commit/0413561261a2fc01caf72e097c516abe6e171060
Let’s start by reviewing the files that have changed:
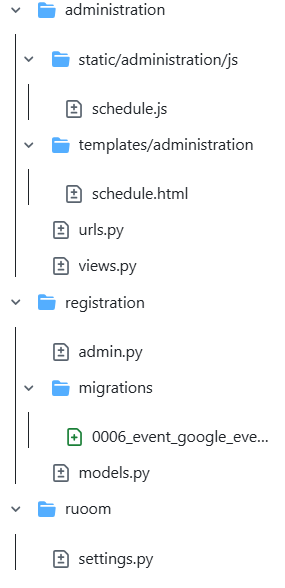
The LLM did not create any files, so we can isolate the files with meaningful edits to the code worth reviewing in this blog:
- schedule.js
- schedule.html
- administration/urls.py
- administration/views.py
- registration/models.py
Populating Skeleton Events (schedule.js)
In the LLM prompting experiment, we began with core open source code that did not natively support a database model for events. To populate events, we created a skeleton Event object based on our Booking plugin. All this occurred prior to letting the LLM loose on the code.
When we began with the LLM, we asked it to start by adding events to our CRM calendar. It has done this in an efficient manner which is very similar to how Google Calendar events were added in our first blog experiment:

However, not to be annoyingly repetitive, but the removal of the first Events line we don’t think is necessary, and it will interfere with our Booking plugin code. We discussed this at length in our last review blog, so let’s move on.
Publish Calendar Button (schedule.html)
In our Schedule page, the LLM has simply added a button to manually publish the CRM calendar to Google Calendar:

Reminder of our original prompt:
I need you to create a feature by which a user might publish the objects in the Events database to their personal Google Calendar account.
The LLM has decided to make this a manual, one-off action, not a continuous sync. You could argue that our prompt left this open to interpretation, so fine.
A continuous sync of events would be more functional than a manual push-button, but this at least addresses our request and proves the concept.
We will be going in-depth into the UI/UX design of the LLM in a future blog, but for this review we’ll just call out the complete lack of a UI that the LLM chose to create here. When the user clicks the button for the first time, they are taken to a Google Single Sign-on page. After this, there is no feedback given to the user whether they are currently synced or if the “Publish” was successful.
In the first Google Calendar integration experiment regarding importing events, the LLM created a UI element indicating Google Calendar Connected.

Last time, we thought this was bare minimum. This time, we’ve learned just how many corners the LLM might cut.

A simple Connected badge would have been valuable, or some varying UI elements depending if the user was already authenticated.
Finally, the biggest issue with the UI on this page was that the first Publish button press doesn’t actually Publish; it just authenticates the user. Users have to click Publish a second time to get it to actually work, and are greeted with this charming page:

It has never been more clear that the LLM will not build you common-sense UI elements unless you explicitly ask for them.
Stay tuned for a future blog when we dive into this in more detail.
Augmented Event Model for Google ID (registration/models.py)
In order to synchronize & update events between Ruoom and Google, the LLM thought it necessary to add one new property to our Event model:

This was a great idea.
It serves an important function and it is well executed. No notes!
Without this property, Ruoom would be constantly creating events in Google, not knowing if they were already created.
Back-end Google Integration (administration/urls.py and views.py)
The LLM made 4 URL endpoints for this integration:
- ScheduleEvents
- GoogleOAuthStart
- GoogleOAuthCallback
- PublishEventsToGoogleCalendar
Looking at views.py, we can evaluate each back-end function.
ScheduleEvents
ScheduleEvents is the endpoint created to populate the Schedule page calendar with the skeleton Event database model. It receives a start date, end date, and location from the front end and returns a list of events as a JSON response. It seems to have decent error handling. But where it does the event filtering, we’re seeing a small problem:

In this if/then block, the LLM is trying to filter events in qs that start after start_dt and end before end_dt (by the way, the variable name qs is weird and we don’t know what it’s supposed to stand for…).
However, the first if statement, which is supposed to check both start_dt and end_dt, only checks for end_dt! We’re not filtering based on start_dt at all and eventually we’re going to crash the front end by asking it to render a thousand events at once. We only had 2 events in the database this time so we didn’t notice the issue.
To fix it, we’d probably just remove the first if statement altogether and let it filter independently on start_dt and end_dt.
GoogleOAuthStart and GoogleOAuthCallback
These two functions serve the same purposes as functions written by the LLM in the last experiment. Comparing the two implementations, we can make the following observations:
- In the first experiment, the LLM used a series of smaller functions to break up commonly used code (DRY: Don’t Repeat Yourself).
- In the second, each function was a longer series of commands with no sub-functions.
- In the first, the LLM had functions untethered to any larger class.
- In the second, each function was a formal View class.
- Both implementations preserve the same general sequence of API actions for performing OAuth.
- Both implementations are very sparse in their use of comments.
- Neither implementation encrypted user credentials in the database. Come on, are we the only ones who see that?

In summary, the use of DRY code makes the first implementation stronger. However, we prefer the View class usage of the second implementation. These are subjective differences, but the best code would be obtained by taking the best parts of each implementation. And adding more comments.
PublishEventsToGoogleCalendar
This endpoint runs the primary function of our feature. It fetches Google OAuth credentials, fetches a list of events to push, and submits the new or updated events to Google Calendar. If the event already exists in Google Calendar, it simply updates the event. All of this works well from a user’s perspective (as long as they are already authenticated), which is a great start.
The first thing we notice is there is not a single comment. Ugh for real.

Next, if the user is not authenticated, the function redirects them straight to OAuth. There is no mechanism to redirect a user from OAuth back to this function, meaning the user has to click the button a second time to get the Publish to work. Not great.
The next observation:
When it fetches events to push to Google Calendar, it filters the database for ALL EVENTS before publishing them one by one. This is highly likely to slow down or time-out our app at some point.
To avoid a crash, we should simply fetch events for the current calendar view, or maybe even the current month or year. We might need some UI language to educate the user on what range of events to expect to be published.
Finally, the returned value of this endpoint is the JSON indicating the successful creation or update of Google Calendar events. Remember, when the user enters the workflow, they are taken to a plaintext page displaying this JSON.
We believe this is a miscommunication between the LLM and itself. It wrote the front-end believing that the back-end would redirect to an HTML page. It wrote the back-end believing that the front-end was using a javascript REST call to fetch information & display it dynamically. We would have expected this from two siloed developers, but not from a single LLM prompt.
Conclusions
Another LLM experiment, and another list of ways that the LLM can misdirect you and let you down! It continues to be an immensely powerful tools, with a range of pitfalls. Some predictable, and some completely wild.
For many of the common pitfalls (no comments in the code, unencrypted credentials, etc) we should be able to create an “Agent” by indicating to the LLM common coding patterns we with it to adhere to. Other pitfalls are always going to be unpredictable, which just highlights the need for human oversight.
There do exist AI tools to review code. Perhaps we will explore these tools in a future blog.
Will they find the same issues as we do, and will they automate their correction?Stay tuned over the next few weeks as we keep exploring.